How do you define natural language processing?
Natural Language Processing is the technology used to aid computers to understand the human’s natural language. In simple terms, converting text into structured data. The ultimate objective of NLP is to read, decipher, understand, and make sense of human languages in a manner that is valuable to machines/computers.
What are the different Machine Translation Models?
Statistical: Statistical method find a word-to-word correspondence in order to translate the language.
Rule-based: Rule-based methods use the grammar rules for the translation.
Hybrid: Hybrid takes advantage of both Statistical and Rule-based methods.
Neural: The recent advancement in MT is neural networks.
How can you differentiate between NLG and NLU?
NLU (Natural language understanding) is the process of reading and interpreting language. Converting Natural language to structure data. Ex- sentiment analysis, Profanity filters, Topic/Document classification, Entity detection.
NLG (Natural Language Generation) is the process of writing or generating language. Converting structure data to Natural language. Ex- Automated Journalism.
Give an example of NLG, NLU and also give an example that used both?
NLU: Sentiment analysis, Profanity filters, Topic/Document classification, Entity detection
NLG: Automated Journalism
NLU and NLG: Virtual Assistant, Chatbot
What is the different type of Approaches used for Hate detection?
• Keyword approach
• Source Meta Data
Keyword approach: For identifying hate speech, by using dictionary text that contains potentially hateful keywords are identified. Keyword-based approaches are fast and straightforward to understand. However, there is a severe limitation. For example: including terms that could or not always hateful. For example, trash, swine. Further keywords-based approaches could not identify hate speech. For example, hate speech that does not have any hateful keywords. Build that wire literally means constructing a wire. However, with the political context, some interpreted these as a condemnation of some immigrants in the United States.
Source MetaData: Additional information from social media can potentially lead to better identification approach. Information such as demographics of the posting user, location, timestamp, or even social engagement on the platform can all give further understanding. However, this information is not legally available to the external researcher because sensitive user information/data raises privacy concerns.
How are the processes of spam classification and machine translation different from each other?
Spam classification is NLU and Machine translation is both NLU and NLG, also spam uses binary classification, while machine translation multi-class classification
Spam classification is a binary classification problem and not necessarily require understanding the context and semantics of sentences. We can implement a simple dictionary-based spam classifier. On the other hand, machine translation is a sequence-to-sequence problem. The MT model must understand the semantics, relationships and context of the words. The model needs to store the state. RNN architectures are necessary such as Encoder-Decoder architecture, transformer architecture, and so on.
What are some example problems of NLP/Text Mining?
-
-
- Sentiment Analysis
- Topic Classification
- Profane filters
- Spam Filtering
- Fraud detection
- Risk Management
- Knowledge Management
- Cybercrime Prevention
- Customer Care Service
- Fraud Detection Through Claims Investigation
- Contextual Advertising
- Business Intelligence
- Content Enrichment
- Spam Filtering
- Social Media Data Analysis
- Contextual Advertisement
-
What are the typical steps of a text mining system involving machine learning?
-
-
- Tokenization
- Part of speech Tagging
- Text Feature Extraction
-
Tokenization: Tokenization is one of the first steps in NLP, and it’s the task of splitting a sequence of text into units. We have word-level tokenization, character-based tokenization, Subword level tokenization.
Part of Speech Tagging: The act of establishing the part of speech of each token in a text and then marking it as such is known as Part of Speech tagging (or PoS tagging). We employ PoS tagging to determine whether a token identified as a noun, verb, adjective, adverb, etc. It is not a simple task: Book a hotel (here book is a verb).
Text feature extraction: Requires machine learning
What is the difference between tokenizing the space-delimited language and unsegmented language?
It consists only of splitting a sentence by the whitespace and punctuation marks. Many logographic (character-based) languages, such as Chinese, have no space breaks between words. Tokenizing these languages requires the use of machine learning.
What are the various Pre Processing techniques in Text Mining?
Tokenization | Stemming, Lemmatization, Contractions, and Typos
Filtering: Stop Words | Accented Words | URLs | Special characters | Numbers | Punctuations
Tokenization is one of the first steps in NLP, and it’s the task of splitting a sequence of text into units. We have word-level tokenization, character-based tokenization, Subword level tokenization.
Word-Level Tokenization: It consists only of splitting a sentence by the whitespace and punctuation marks. There are plenty of libraries in Python that do this, including NLTK, SpaCy, Keras, Gensim or you can do a custom Regex.
Many logographic (character-based) languages, such as Chinese, have no space breaks between words. Tokenizing these languages requires the use of machine learning, and is beyond the scope of this article.
Stemming and Lemmatization both generate the root form of the inflected words. The difference is that stem might not be an actual word whereas, lemma is an actual language word.
Stemming Example: ponies -> poni (Poni is not a dictionary word)
Lemmatization Example -> pony (it is a dictionary word)
Stemming follows an algorithm with steps to perform on the words which makes it faster. Whereas, in lemmatization, you used WordNet corpus and a corpus for stop words as well to produce lemma which makes it slower than stemming. You also had to define a parts-of-speech to obtain the correct lemma.
A contraction is a shortened form of the word (or group of words) that omits certain letters or sounds.
Ex: We’re (we are), I’d (I would)
I’d like to know who you’re I would like to know who you are
Typos: is simply spelling mistakes, we need to remove the spelling mistakes for a given word in the document.
Stop Words: Stop words are commonly used words of a language that may not add much information to the task.
Ex: (to, the, a, is, are) do not relate much to document classification
What is tokenization?
Tokenization is one of the first steps in NLP, and it’s the task of splitting a sequence of text into units. We have word level tokenization, character-based tokenization, Subword level tokenization.
Word-Level Tokenization: It consists only of splitting a sentence by the whitespace and punctuation marks. There are plenty of libraries in Python that do this, including NLTK, SpaCy, Keras, Gensim or you can do a custom Regex.
Many logographic (character-based) languages, such as Chinese, have no space breaks between words. Tokenizing these languages requires the use of machine learning, and is beyond the scope of this article.
What are Stemming and Lemmatization?
Stemming and Lemmatization both generate the root form of the inflected words. The difference is that stem might not be an actual word whereas, the lemma is an actual language word.
Stemming: ponies -> poni (Poni is not a dictionary word)
Lemmatization -> pony (it is a dictionary word)
Stemming follows an algorithm with steps to perform on the words which makes it faster. Whereas, in lemmatization, you used WordNet corpus and a corpus for stop words as well to produce lemma which makes it slower than stemming. You also had to define a parts-of-speech to obtain the correct lemma.
Suppose you are developing machine translation, which preprocessing steps you will do OR will not do?
You don’t need lemmatization/stemming, stopwords removal. I am not sure if we should not remove numbers also. Probably URL can be removed and accented words and contractions can be replaced.
For which task is an (MLP|RNN|CNN) useful?
MLP for any tasks but requires a lot of computing power due to fully connected layers. So, MLP is good for small problems. RNN for the sequence to sequence or time series problems. CNN for images (object detection / classification) and sequence with fixed length (approximately 100 to 200).
What is the difference b/w Neural Networks and RNN
In traditional feedforward neural networks, all the inputs, and outputs are independent of each other. RNN unit takes the current input (X) as well as the previous input (A) to produce output (H) and current state (A)
The RNN can take a sequence of values of inputs and take series of values as outputs. Which opens a wide variety of applications.
When an input is singular and output is a sequence, the potential application is image captioning. A multiple-input with single output can be thought of as document classification. When input and output are sequences, it can be thinking of language translation.
What is the vanishing gradient problem and how it is tackled?
Problems with RNN (Hard to train, Vanishing Gradient problem)
RNN is an extremely difficult network to train, the gradient is exponentially worst for RNN. For example, training an RNN for 100-time steps is like training a 100-layer neural network. This leads to exponentially small gradients, and decay of information through time and which does not help in updating the weights/word embeddings. One of the ways to tackle vanishing gradient is the Gated unit’s LSTM, GRU.
How does LSTM work? Why is it useful and when?
Use of LSTM to tackle the problem of vanishing gradient.
Long Short-Term Memory networks — usually just called LSTMs — are a special kind of RNN, capable of learning long-term dependencies. LSTM does it by keeping the useful information and forgetting which is not meaningful. In LSTMs, the information flows through a mechanism known as cell states. The addition or removal of information is controlled by gates at each cell. A value of zero means let nothing through, while a value of one means let everything through. An LSTM has three of these gates to control the cell state.
Forget Gate: This gate decides what information we’re going to throw away from the cell state.
Input Gate: which outputs numbers between 0 and 1 and decides which values to update.
Output Gate: Finally, we need to decide what we’re going to output. This output will be based on our cell state.
Explain the following in a language, and give examples: Morphemes, lexemes, syntax, and context.
Phonemes: A unit of sound in language
Morphemes: The smallest unit in language with meaning.
Lexemes: Consist of one or more morphemes, that are connected by inflections. (Word, Token)
Syntax: Set of rules that create structure
Context: The surroundings of a word/text, that help the meaning of that particular/word
Sentence: She likes Pizza
Phonemes: Sound notations: unit of sound
Morphemes: She | Likes | Pizza (There are three morphemes)
Lexemes: She | Likes | Pizza (There are three lexemes: Token/Words)
Syntax: She (Subject) likes(Verb) Pizza(Object)
Context: Context of likes is She and Pizza
What is a POS tag? Make a sentence, and POS tag it.
PoS tagging means assigning parts of speech to tokens. Part of speech tags like nouns, adverbs. Example: She (pronoun), likes (verb), pizza (noun)
Describe the multi-class, multi-label, and multi-task classification problems.
Multi-class classification: When a sentence/word can have multiple classes. ex: a fruit can be either an apple or a pear but not both at the same time.
Multi-label classification: When a sentence/word can have multiple labels. ex: a movie can have multiple genres at the same time
Multi-task classification: When we split the main model into sub-models that they can run simultaneously and use different loss functions. The sub-models share with each other what is learned for each task and help other tasks to perform better.
Name two similarity measurement metrics for vectorized semantic representation, and tell which one is preferred? Why?
Two similarity measurement metrics for vectorized semantic representation are Euclidean and Cosine distances.
Euclidean distance considers magnitude and angle, while Cosine considers the angle between two vectors. Cosine distance is more preferred than Euclidean distance since the magnitude of vectors doesn’t give much information.
What are the different types of documents, what is document classification, provide some examples?

What do you understand by Gender Bias?
Gender Bias is when we have errors in recognizing the right gender for a given instance, it mostly happens for women. For example, the AI system needs to fill in the blanks, Man is to the king, a woman is to Queen. The underlying issue arises in cases where AI fills in sentences like “Father is to doctor as a mother is to nurse.” The inherent gender bias in the remark reflects an outdated perception of women in our society that is not based on fact or equality.
AI-based Systems for gender recognition reported higher error rates for recognizing women.
Best Practices for Machine-Learning Teams to Avoid Gender Bias
• Ensure diversity in the training samples (e.g. use roughly as many female audio samples as males in your training data).
• Ensure that humans labeling the audio samples come from diverse backgrounds.
What is semantics and how we can represent it? Specifically, discuss formal and vectorized semantic representation and give examples of each.
Semantic approach (relating to meaning in language -> stretch the words beyond, understanding ambiguities) Word2Vec (Skip and CBOW)

What is a virtual assistant and explain briefly how does it work?
A virtual assistant (VA) is an advanced computer program that can understand, process, learn from, and respond to voice or text inputs in natural ways. It typically combines advanced natural language processing (NLP), natural language understanding (NLU).
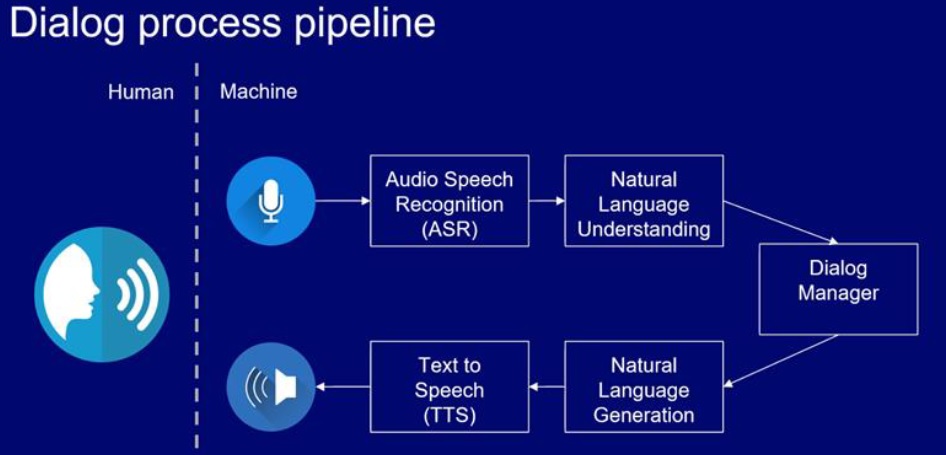
1.Capture the voice | 2. Recognizing language and converting it to text (using ASR) 3. Understanding the semantics using NLU | 4. Dialog manager to search and generate results for the given query| 5. Then generating the text for the given problem using NLG | 6. Then converting the text to speech 7. Then writing the speech output to the speaker.
Justify why we use regularization methods, list the three major categories of regularization methods we discussed, and explain one of them in more detail.
Regularization is a set of techniques that can prevent overfitting in neural networks. Three methods L1, L2, dropout. The main intuitive difference between the L1 and L2 regularization is that L1 regularization tries to estimate the median of the data while L2 regularization tries to estimate the mean of the data to avoid overfitting. That’s the main intuitive difference between the L1 (Lasso) and L2 (Ridge) regularization techniques. L1 regularization adds the penalty term in the cost function by adding the absolute value of weight(Wj) parameters, while L2 regularization adds the squared value of weights(Wj) in the cost function.
What is the difference between Syntactic and Semantic analysis, how parser can be applied as a method of syntactic analysis?
Syntactic analysis (syntax) and Semantic analysis (semantic) are the two primary techniques that lead to the understanding of natural language.
The syntax is the grammatical structure of the text, whereas semantics is the meaning being conveyed. A sentence that is syntactically correct, however, is not always semantically correct. For example, “cows flow supremely” is grammatically valid (subject-verb — adverb) but it doesn’t make any sense.
parse is to “resolve a sentence into its component parts and describe their syntactic roles.”
Parsing refers to the formal analysis of a sentence by a computer into its constituents, which results in a parse tree showing their syntactic relation to one another in visual form, which can be used for further processing and understanding.
It helps in identifying parts of speech, Phrases, and relationships.
In human language we have polysemy and synonymy, what is the difference between them? Based on the above, what is synset in NLP?
Polysemy: One word expresses multiple meanings. ( A financial bank | A river bank)
Synonymy: One concept is expressed by several different forms of words (author/writer, beat/hit/strike)
WordNet is the lexical database i.e. dictionary for the English language, specifically designed for natural language processing.
Synset is a special kind of simple interface that is present in NLTK to look up words in WordNet. Synset instances are the groupings of synonymous words that express the same concept. Some of the words have only one Synset and some have several.
Can CNN apply for NLP or just for computers, justify your answer?
Yes, it can be applied for NLP. CNN’s are good at extracting local and position-invariant features whereas RNN’s are better when classification is determined by a long-range semantic dependency rather than some local key-phrases. For tasks where feature detection in the text is more important, for example, searching for angry terms, sadness, abuses, named entities, etc. CNN’s work well whereas for tasks where sequential modeling is more important, RNN’s work better. Based on the above characterization, it makes sense to choose a CNN for classification tasks like sentiment classification since sentiment is usually determined by some key phrases and to choose RNNs for a sequence modeling task like language modeling or machine translation, or image captioning as it requires flexible modeling of context dependencies. RNNs usually are good at predicting what comes next in a sequence while CNNs can learn to classify a sentence or a paragraph.
A big argument for CNNs is that they are fast. Very fast. Based on computation time CNN seems to be much faster (~ 5x ) than RNN. Convolutions are a central part of computer graphics and implemented on a hardware level on GPUs. Applications like text classification or sentiment analysis don’t actually need to use the information stored in the sequential nature of the data.
Explain the main idea behind FastText word representation?
One of the main disadvantages of Word2Vec and GloVe embedding is that they are unable to encode unknown or out-of-vocabulary words.
So, to deal with this problem Facebook proposed a model FastText. It is an extension to Word2Vec and follows the same Skip-gram and CBOW model. but unlike Word2Vec which feeds whole words into the neural network, FastText first breaks the words into several sub-words (or n-grams) and then feeds them into the neural network.
List some of the practical issues that NN might face and come up with some suggestions for the solution?
Common issues in neural network implementations:
-
-
- Computationally expensive: A neural network is also computationally expensive and time-consuming to train with traditional CPUs.
- Amount of Data: Neural networks typically require much more data than traditional machine learning algorithms. Though there are some cases where neural networks perform well with a small amount of data, most of the time they don’t. In this case, several simple algorithms out there like naive Bayes that deal much better with minimum data, would offer a better opportunity. Moreover, neural networks rely more on training data that leads to the problem of overfitting and generalization.
- Black Box: The very most disadvantage of a neural network is its black-box nature. Because it has the ability to approximate any function, it studies its structure but doesn’t give any insights on the structure of the function being approximated. So, understanding the cause of the mistake requires features that are human interpretable. This is significant because, in some domains, interpretability is critical. And that is the reason why most banks don’t leverage neural networks to predict whether a person is creditworthy as they need to explain to him/her why they didn’t get the loan, if not the person may feel unfairly treated.
-
What is the idea behind using N-Grams in NLP?
N-gram means that how many words you are considering as a single unit when you are calculating the frequency of words. An n-gram model, instead, looks at the previous (n-1) words to estimate the next one.
What is the difference between tokenizing the space-delimited language and unsegmented language?
English is a space-delimited language, it is easy to tokenize such language. Whereas in the case of unsegmented language, which is a logographic we use machine learning to separate words or tokenize.
What is Word Embedding (Also referred to as Feature Extraction techniques in NLP?
Vectorization or word embedding is nothing but the process of converting text data to numerical vectors. Later the numerical vectors are used to build various machine learning models. In a way, we say this as extracting features from text to build multiple natural languages, processing models.
What is popular Word Embedding Techniques
There are numerous ways to convert the text data to numerical vectors, refer to as word embedding techniques.
Bag of words | TF-IDF | Word2vec | Glove embedding | FastText | ELMO (Embeddings for Language models).
Describe a language model, and explain two methods one can use to evaluate it (one extrinsic, and one intrinsic)
A language model is a statistical model that assigns probabilities to words and sentences. Typically, we might be trying to guess the next word w in a sentence given all previous words, often referred to as the “history”.
Extrinsic evaluation. This involves evaluating the models by employing them in an actual task (such as machine translation) and looking at their final loss/accuracy. This is the best option as it’s the only way to tangibly see how different models affect the task we’re interested in. However, it can be computationally expensive and slow as it requires training a full system.
Intrinsic evaluation. This involves finding some metric to evaluate the language model itself, not taking into account the specific tasks it’s going to be used for. While intrinsic evaluation is not as “good” as extrinsic evaluation as a final metric, it’s a useful way of quickly comparing models. Perplexity is an intrinsic evaluation method.
What are context vectors, encoders, and decoders in recurrent neural networks?
Encoder reads the input sequence and summarizes the information in something called the internal state vectors or context vector (in the case of LSTM these are called the hidden state and cell state vectors).
The decoder is an LSTM whose initial states are initialized to the final states of the Encoder LSTM. Using these initial states, the decoder starts generating the output sequence, and these outputs are also taken into consideration for future outputs.
Describe the model architecture of the encoder-decoder network for translation, in both phases of training and inference.
The model takes an input sequence and outputs a sequence as output (i.e., many-to-many) is known as the sequence-to-sequence task. The sequence-to-sequence tasks are very challenging as the size of the inputs and outputs vary.
To tackle many-to-many sequence prediction problems, researchers have explored and found a way in the form of Encoder-Decoder Architecture.
Encoder-Decoder Model: There are three main blocks in the encoder-decoder model,
Encoder | Hidden Vector | Decoder
The Encoder will convert the input sequence into a single-dimensional vector (hidden vector). The decoder will convert the hidden vector into the output sequence. Encoder-Decoder models are jointly trained to maximize the conditional probabilities of the target sequence given the input sequence.
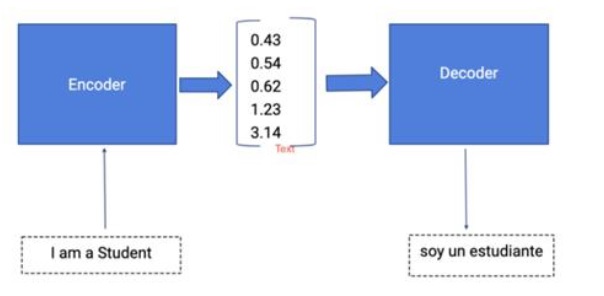
Encoder: Consider the input sequence “I am a Student” to be encoded. There will be totally 4 timesteps ( 4 tokens) for the Encoder model. At each time step, the hidden state h will be updated using the previous hidden state and the current input.
Decoder: The input for the decoder is the final hidden vector obtained at the end of the encoder model.
What is one hot encoding? length of encoding depends upon what?
One hot encoding: It is one of the techniques to represent features. Features are represented using a binary vector. The size of the vector depends upon the vocabulary. For n-words sentences, we have nxv, where v is the size of the vocabulary.
What is word2vec
Word2Vec is one of the most popular techniques to learn word embeddings using a shallow neural network. Words with similar contexts are placed closed spatially. It helps achieve the semantic meaning of the word.
It can be obtained using two methods (both involving Neural Networks): Skip Gram and Common Bag of Words (CBOW)
Like we have the concept of N-gram in the bag of words, here we have a concept of Window size. The Word2vec model will capture relationships of words with the help of window size by using skip-gram and CBow methods. We use a window to keep track of the center word and the context of the center word.
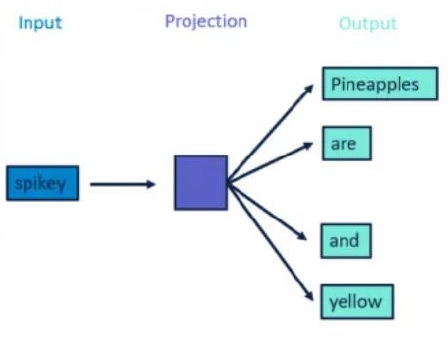
What is Word2Vec – Skip Gram?
In this method, take the center word from the window size words as an input and context words (neighbor words) as outputs. Word2vec models predict the context words of a center word using the skip-gram method. Skip-gram works well with a small dataset and identifies rare words really well.
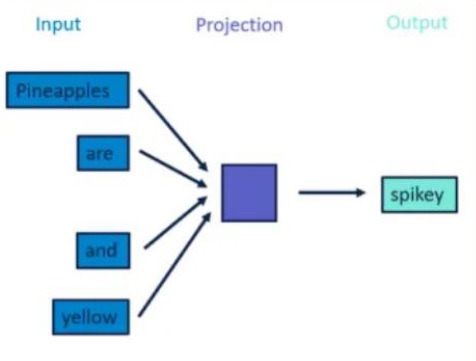
What is Word2Vec- CBOW (Continuous Bag of Words)
CBOW is just a reverse method of the skip-gram method. Here we are taking context words as input and predicting the center word within the window. Another difference from the skip-gram method is, It was working faster and better representations for most frequency words.
What is the difference b/w Skip-gram and CBOW

What is Bag of Words: Word embedded Technique?
This method is mostly used in language modeling and text classification tasks. In a bag of words, we perform two operations. Tokenization and Vectors Creation.
Tokenization: The process of dividing each sentence into words or smaller parts. Here each word or symbol is called a token. After tokenization, we will take unique words from the corpus. Here corpus means the tokens we have from all the documents we are considering for the bag of words creation.
Create vectors for each sentence: Size of the vector is equal to the number of unique words of the corpus. For each sentence we will fill each position of a vector with corresponding word frequency in a particular sentence.
Consider three below sentence:
-
-
- this pasta is very tasty and affordable
- this pasta is not tasty and is affordable
- this pasta is very very delicious
-
Now we will perform tokenization. Dividing sentences into words and creating a list with all unique words and also in alphabetical order. We will get the below output after the tokenization step.
[“and”, “affordable”, “delicious”, “is”, “not”, “pasta”, “tasty”, “this”, “very”]
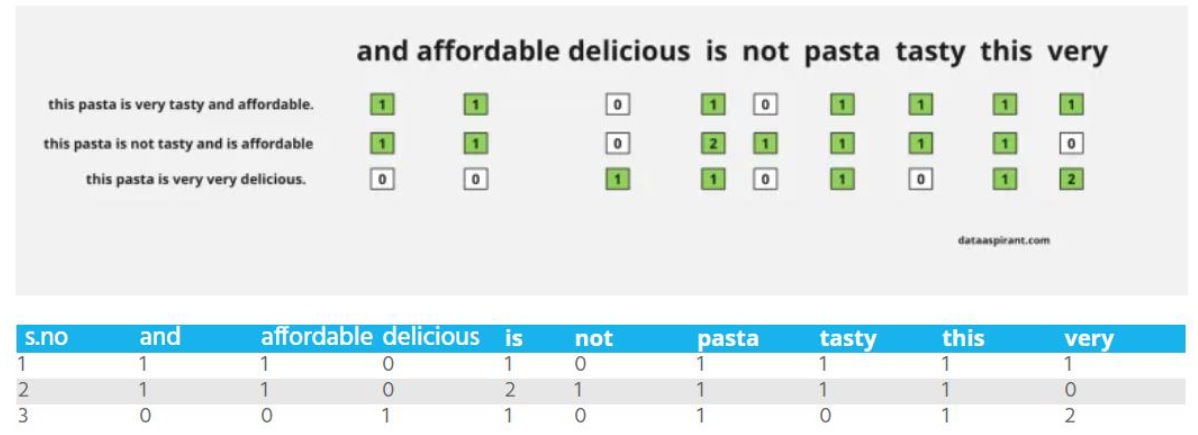
every sentence converting into vectors. We can also find sentence similarities after converting sentences to vectors.
In the above example, we are just taking each word as a feature, another name for this is 1-gram representee, we can also take bigram words, tri-Gram words, etc..
What is the demerit of Bag of Words Technique?
In Bag of word representation, we have more zeros in the sparse matrices. The size of the matrix will be increased based on the total number of words in the corpus. In real-world applications, the corpus will contain thousands of words. So, we need more resources to build analytics models with this type of technique for large datasets.
We need serious computing resources to build an analytical model based on the bag of words technique.
What is a Good NLP model?
Best models would be able to capture 4 components:
- Lexical approach (relating to the words or vocabulary of a language) (covered by BOW, TF-IDF)
- Syntactic approach (the arrangement of words and phrases to create well-formed sentences in a language -> grammar) One hot encoding.
- Semantic approach (relating to meaning in language -> stretch the words beyond, understanding ambiguities) Word2Vec (Skip CBOW)
- Contextual/Pragmatic approach (relating proximity between words and documents)

